


The European Money and Finance Forum has recently published a useful paper on big data and machine learning in central banks 1. Big data has been part of life for many years, but it continues to change models of data collection, particularly with its ability to analyse non-traditional data. In a 2020 Irving Fisher Committee of the Bank for International Settlements (IFC) survey, more than 80% of central banks report that they use big data, up from 30% five years ago.
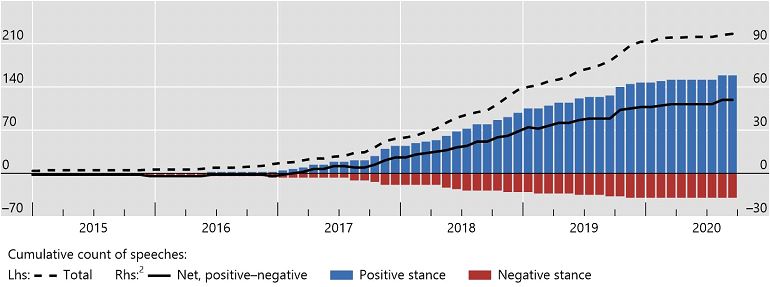
Number of speeches mentioning keywords ‘artificial intelligence’, ‘big data’ or ‘machine learning’. Source: Doerr et al (2021).
Today we are seeing big data combined with novel techniques such as machine learning or natural language processing offering new opportunities to understand the economy and financial system better and to inform policy. This comes, of course, with new challenges.
While 90% of IFC survey respondents report that big data includes unstructured datasets, 80% included datasets with a large number of observations in the time series or cross-section constitute big data. Around two-thirds of respondents considered large, structured databases as big data.
The survey also revealed a wide range of data sources, ranging from structured administrative data sets such as credit registries to unstructured non-traditional data obtained from newspapers, mobile phones, web-scraped property prices, or social media posts.
Big data and machine learning tools are routinely used by more than 80% of central banks for tasks such as economic research, financial stability and monetary policy. Big data are also used for supervision and regulation (suptech and regtech applications) and statistical compilation. Advanced Economies (AEs) and Emerging Market Economies (EMEs) using big data differ by area.
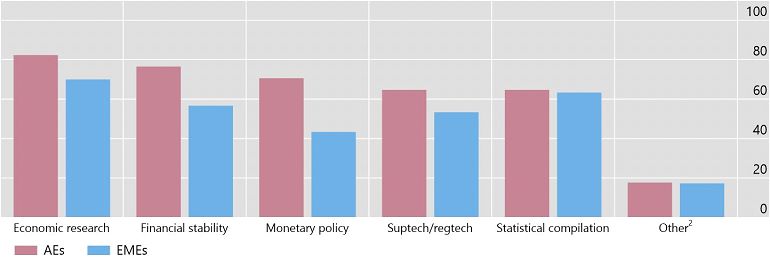
Share of respondents that selected each respective answer to the question ’For what general purposes does your institution use big data?’. Source: Doerr et al (2021).
Supporting traditional economic analysis with Nowcasting models that draw on a variety of data sources, ranging from structured information to datasets retrieved from non-traditional sources. These models produce high-frequency forecasts that can be updated in almost real-time.
Creating economic or policy uncertainty indices from textual data made possible by using natural language processing to produce economic or policy.
Supporting financial stability analysis. In addition to the large proprietary and structured datasets compiled within central banks, the analysis is able to include trade repositories with derivative transactions, credit registries with information on loans, and individual payment transactions.
Around 60% of central banks’ use of big data is for suptech and regtech applications, although at this stage they are largely exploratory. Natural language processing is used to augment traditional credit scoring models, drawing on information from news media or financial statements. Big data algorithms are incipiently used for anti-fraud detection, identifying suspicious payment transactions, and fraudulent loan clauses. Central banks are also supporting the use of regtech applications by financial institutions to meet compliance requirements.
Using big data brings practical challenges such as installing and using the necessary IT infrastructure, providing adequate computing power, finding the right software tools, training existing or hiring new staff.

Share of respondents that selected each respective answer to the question ‘What is the focus of the discussions on big data within your institution?’. Source: Doerr et al (2021).
Alongside those practical challenges are the legalities of using private and confidential data. As more and more data are drawn from other sources outside of the central bank there is the need to consider ethics and privacy, particularly data on users’ search history or web-scraped social media postings.
Data quality, again particularly when drawn from non-traditional sources, is a challenge. Data cleaning (eg. in the case of media, social media or financial data), sampling and representativeness (eg. in the case of web searches or employment websites) and matching new data to existing sources must be done well to create useful data.
Cooperation among public authorities could help with collecting, storing and analysing big data. The European Central Bank’s AnaCredit database collects harmonised data from euro area member states in a single database to support decision-making in monetary policy and macroprudential supervision.
The Bank for International Settlements collects and processes confidential banking data in cooperation with central banks and other national authorities, including the International Banking Statistics, and data collected in the International Data Hub.
To enable this, legal obligations about storing raw data within national boundaries, cloud computing contracts, rules for data use and the protection of confidentiality and protocols to ensure algorithmic fairness need to be considered, developed and ratified.
1 - How do central banks use big data and machine learning?, SUERF Policy Brief .:. SUERF – The European Money and Finance Forum


